|
Lv/Lyu Tang
My name is Lv Tang. I received my Bachelor of Science degree from the School of Information Science and Technology, Southwest Jiaotong University (SWJTU) in 2018. I obtained my Master’s degree from the Department of Computer Science, Nanjing University in 2021. I received my Ph.D. degree from the School of Computer Science and Technology, University of Chinese Academy of Sciences (UCAS) in 2025. I am currently a Postdoctoral Researcher in the Department of Electrical and Computer Engineering at the University of Alberta.
Email /
Resume /
Twitter /
Google Scholar /
Github
|

|
|
Research
I received my Ph.D. degree from the University of Chinese Academy of Sciences (UCAS), where my research focused on large visual models, saliency detection, video compression, camouflaged object detection and image segmentation. Looking ahead, my research interests primarily lie in MLLMs and their applications across various downstream tasks. To date, I have published 12 papers in top-tier conferences and journals, contributing to a total of 30 publications that have accumulated over 1070 citations.
|
News
- 2025-12: One paper is accpeted by TMM 2025.
- 2025-08: One paper is accpeted by Neural Networks 2025.
- 2024-12: Two papers are accpeted by TOMM 2024 and AAAI2025.
- 2024-07: One paper is accpeted by ACMMM 2024.
- 2024-06: One paper is accpeted by IJCV 2024.
- 2024-03: One paper is accepted by TOMM 2024.
- 2024-02: One paper is accepted by CVPR 2024.
|
Selected Publications
|
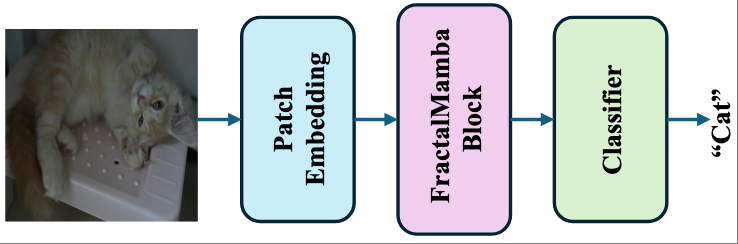
Boosting Vision State Space Model with Fractal Scanning
Haoke Xiao,
Lv Tang*,
Peng-Tao Jiang,
Hao Zhang,
Jinwei Chen,
Bo Li (Corresponding author and Co-first author)
AAAI 2025 (Oral)
|
|
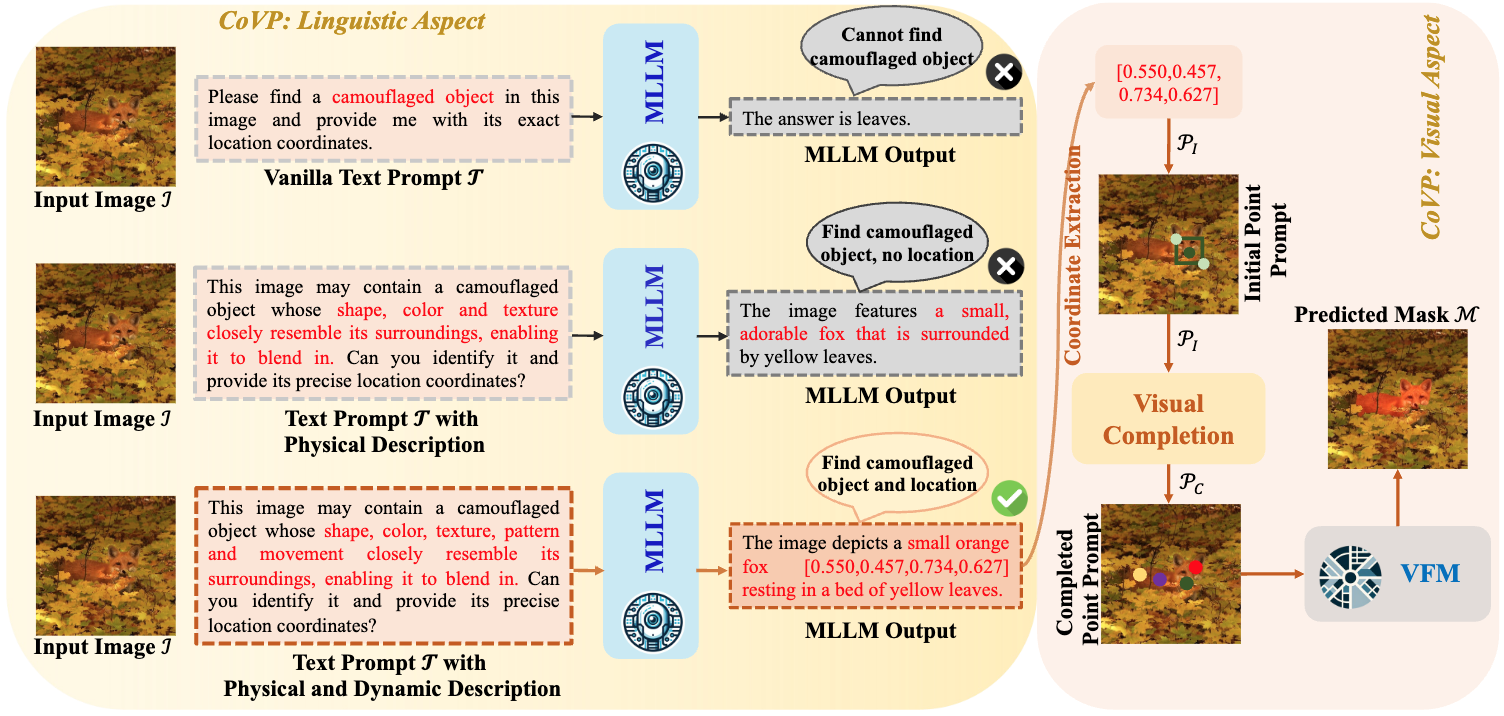
CoVP: Harnessing multimodal large language models for zero-shot camouflaged object detection
Lv Tang,
Peng-Tao Jiang,
Zhi-Hao Shen,
Hao Zhang,
Jinwei Chen,
Bo Li
ACMMM 2024
|
|
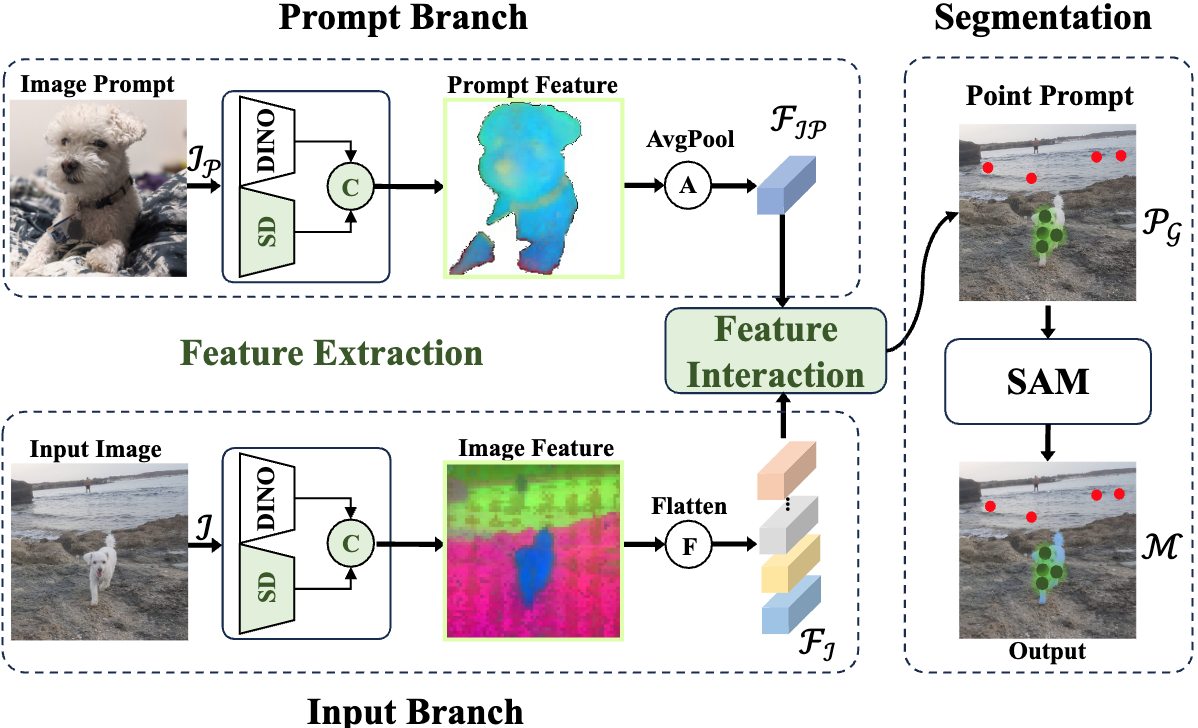
Towards training-free open-world segmentation via image prompting foundation models
Lv Tang,
Peng-Tao Jiang,
Haoke Xiao,
Bo Li
IJCV 2024
|
|
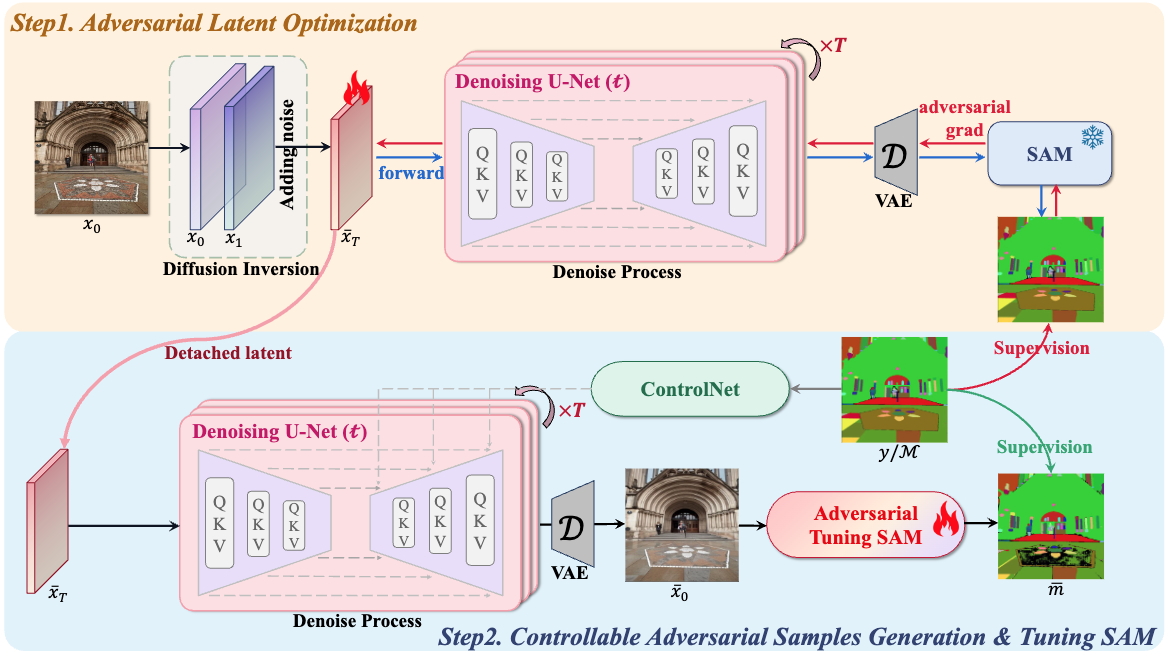
ASAM: boosting segment anything model with adversarial tuning
Bo Li,
Haoke Xiao,
Lv Tang* (Corresponding author)
CVPR 2024
|
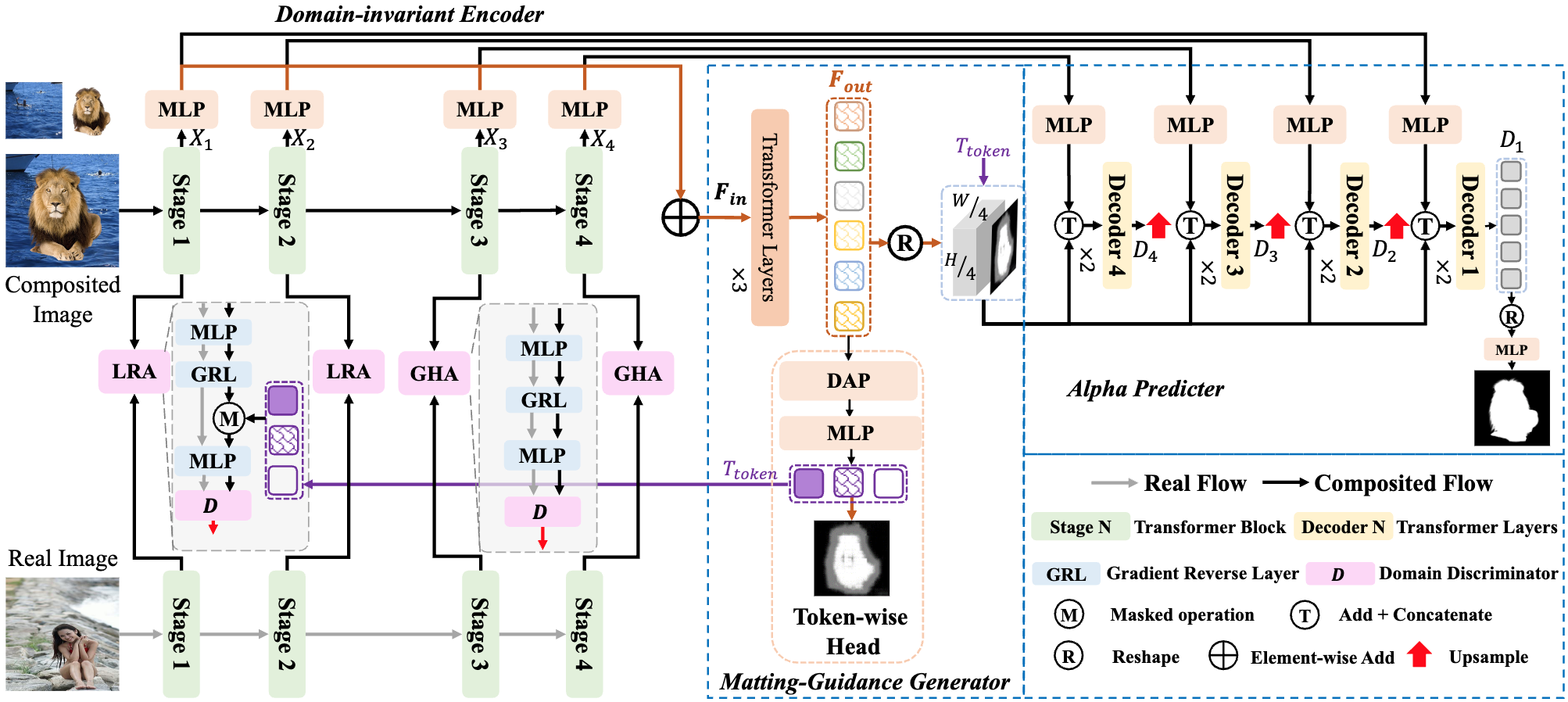
|
From composited to real-world: Transformer-based natural image matting
Yanfeng Wang,
Lv Tang*,
Yi-Jie Zhong,
Bo Li (Corresponding author)
TCSVT 2024
|
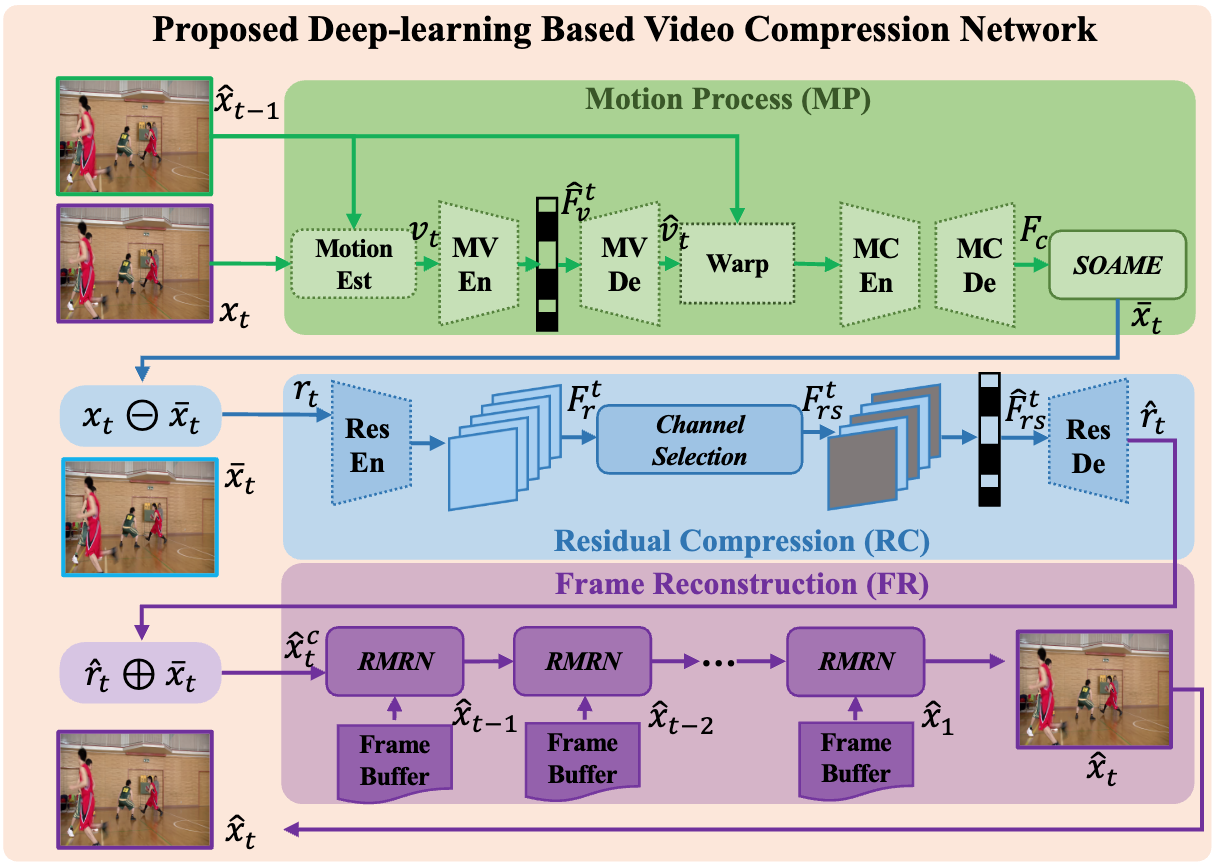
|
High Efficiency Deep-learning Based Video Compression
Lv Tang,
Xinfeng Zhang
TOMM 2024
|
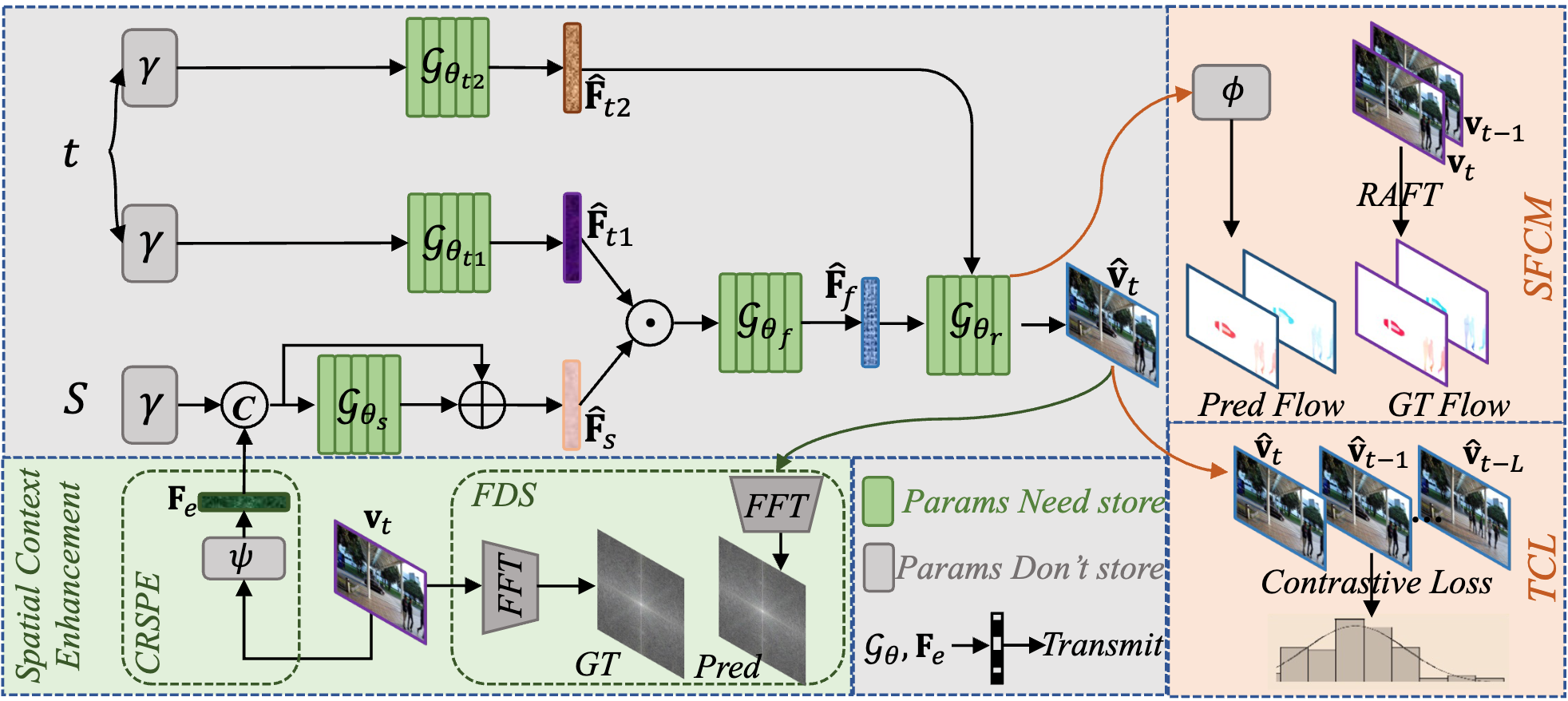
|
Scene Matters: Model-based Deep Video Compression
Lv Tang,
Xinfeng Zhang,
Gai Zhang,
Xiaoqi Ma
ICCV 2023
|
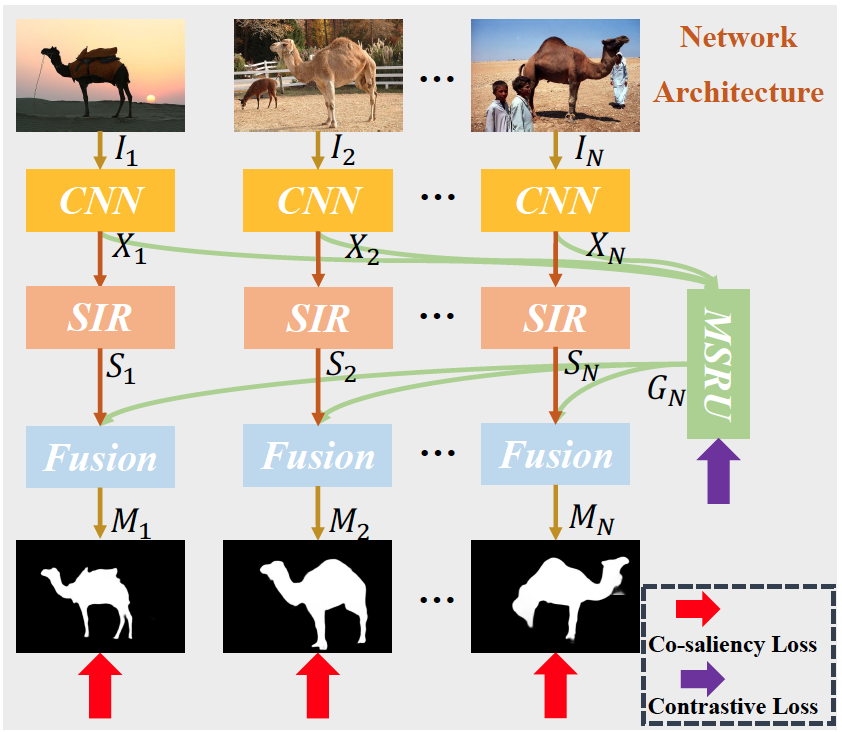
|
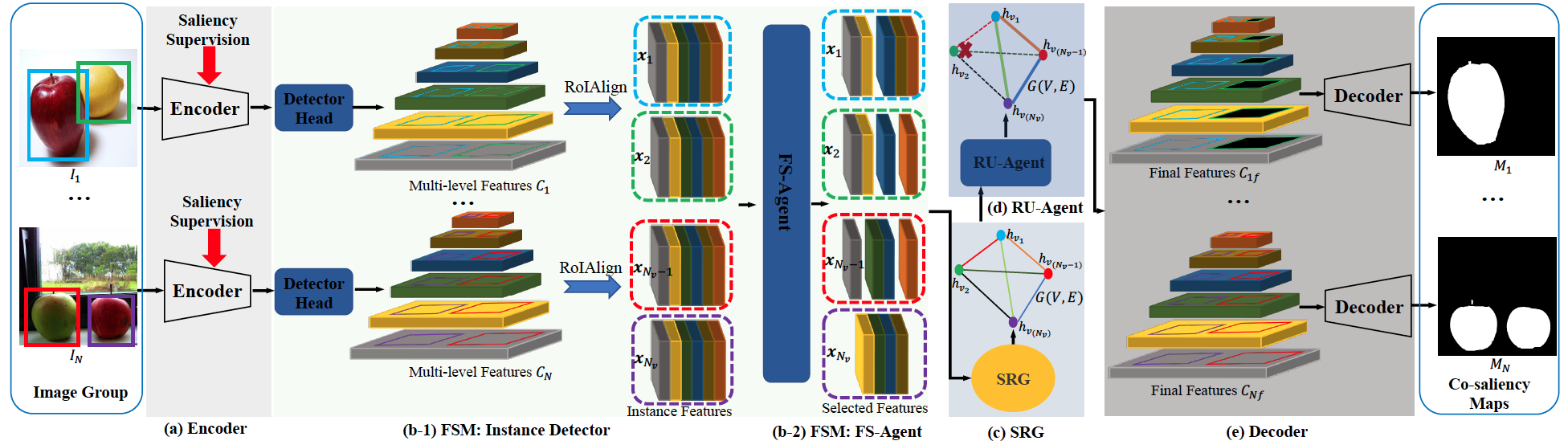
Toward stable co-saliency detection and object co-segmentation
Bo Li,
Lv Tang*,
Senyun Kuang,
Mofei Song,
Shouhong Ding (Corresponding author)
TIP 2022
|
|
Re-thinking the relations in co-saliency detection
Lv Tang,
Bo Li,
Senyun Kuang,
Mofei Song,
Shouhong Ding
TCSVT 2022
|
|
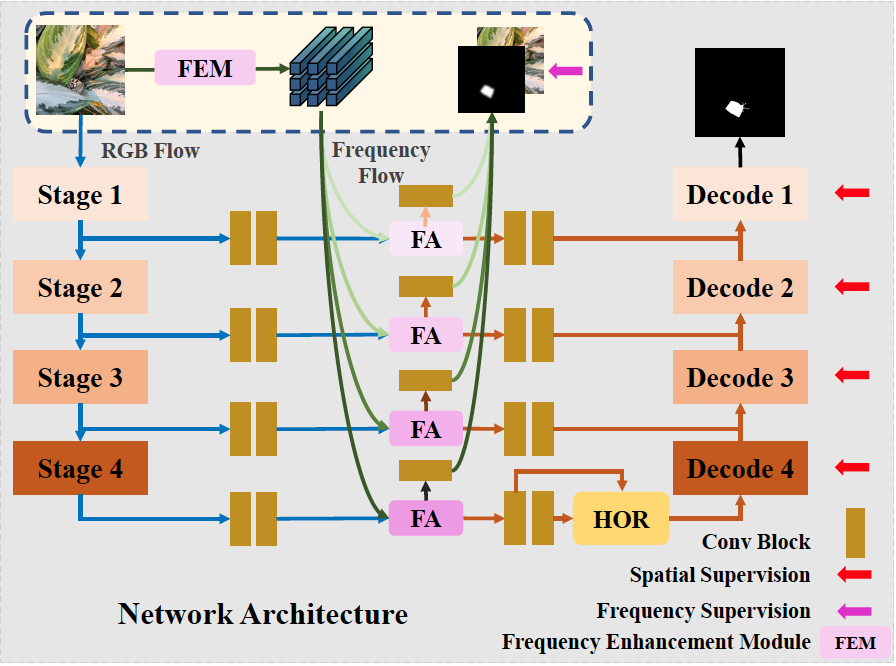
Detecting camouflaged object in frequency domain
Yi-Jie Zhong,
Bo Li,
Lv Tang*#,
Senyun Kuang,
Shuang Wu,
Shouhong Ding (Corresponding and Co-first author)
CVPR 2022
|
|
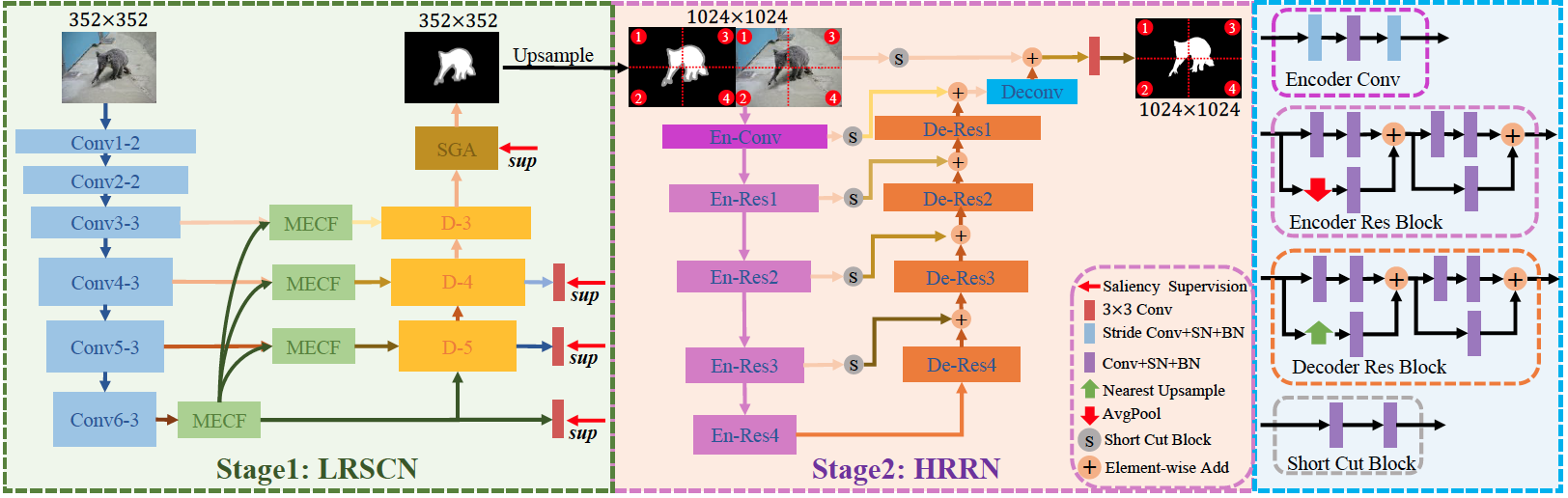
Disentangled high quality salient object detection
Lv Tang,
Bo Li,
Yi-Jie Zhong,
Senyun Kuang,
Shouhong Ding,
Mofei Song
ICCV 2021
|
|